| 实验设计/技术服务导航 | |||||||||
|
|||||||||
|
|||||||||
|
|||||||||
数据分析服务 世联博研数据分析团队由来自微软、华为、中科院、农科院的力学、生物信息学、计算机专业人员组成,其中博士以上学历者占50%以上,在图像处理、蛋白质组学、转录组学、基因组学、数值模拟及数据可视化处理方面拥有丰富的经验。公司建立了高性能计算平台,具有强大的数据储存和处理能力,使用Linux、R、Perl、Python、C++等工具进行数据处理,可为客户定制数据分析服务并提供咨询,将符合期刊发表要求的结果发送给客户。
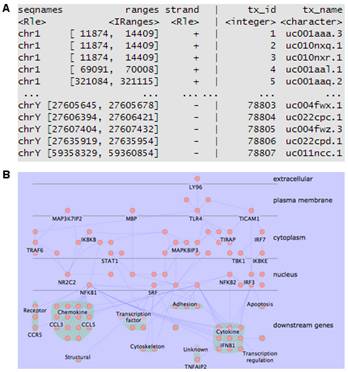
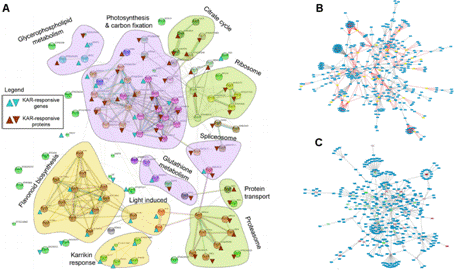
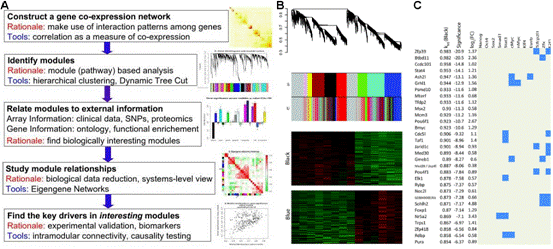
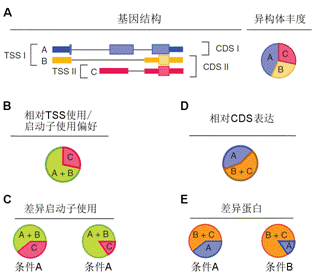
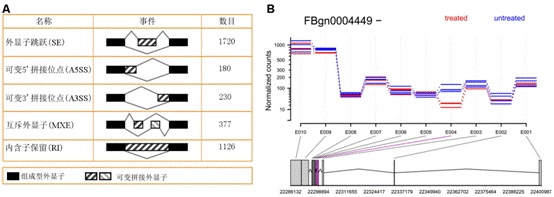
聚类分析(cluster analysis)是一类将数据所研究对象进行分类的统计方法。这一类方法的共同点是事先不知道类别的个数与结构;据以进行分析的数据是对象之间的相似性或相异性的数据。将这些相似(相异)性数据看成是对象之间的“距离”远近的一种度量,将距离近的对象归入一类,不同类之间的对象距离较远。这就是聚类分析方法的共同思路。具体在生物学研究中,基因表达谱分析经常采用聚类分析的方法,其目的就是将基因或者样本进行分组。从数学的角度,聚类得到基因分组,组内各成员在数学特征上彼此相似,但与其它组中的成员不同。其基本假设是组内基因的表达谱相似,它们可能具有功能相关性。大量功能相关的基因,te别是被共同的转录因子调控的基因表达谱非常相似,它们的产物可能构成蛋白质复合体,或者处于同一个调控通路中,因此还可以据此推测未知基因的功能并评估实验的合理性(图1)。 聚类分析根据分类对象不同分为Q型聚类和R型聚类。Q型聚类是指对样本进行聚类,R型聚类是指对变量进行聚类分析。根据聚类方法可以分为系统聚类和动态聚类。系统聚类法一次形成类后就不再改变,而动态聚类开始先粗略地分一下类,然后按照某种you原则修改不合理的分类,直至类分得比较合理,如K-均值聚类等,适用于大样本的Q型聚类分析。 2.基因注释实验服务 在基因芯片或者转录组学研究中,得到基因列表之后通常要对高达数千种基因或蛋白进行注释,以得到其各种名字的对应关系、染色体定位及亚细胞定位来方便后续的研究。由于注释数据库的数量在不断增加,且不断进行着各种修改,所以在高通量组学研究中很难对这些信息进行整合。针对这些问题,我们开发了专门的组学数据注释流程,可方便地进行基因ID转换(图2 A),并确定相应蛋白的亚细胞定位,以推测其功能(图2 B)。 3.功能富集分析实验服务 随着转录组学及蛋白质组学的发展,现在已经可以一次性得到大量的基因表达数据。对这些数据进行分析时通常采用功能富集分析的方法(图3),而非仅仅分析单个基因,以避免单基因分析可能产生的偏差,从而得到更准确的结论。进行功能富集分析需要可靠的数据库和强健的算法(如累积超几何分布、Fisher精确检验等),把涉及相同通路和功能的基因/蛋白质进行归类,有助于生物学问题的解决。 4.互作网络分析实验服务 基因编码的蛋白质不但会单行使功能,还会与其它蛋白质之间存在着相互作用,这种相互作用使其功能更加多样化,且可以进行各种调控。所以,随着后基因组时代的到来,蛋白质相互作用研究受到了越来越多的重视。现已有很多数据库和工具进行蛋白互作(包括物理互作和功能互作)数据的储存和处理,其数据主要来自于基因组结构、高通量实验、共表达实验和文献挖掘。将蛋白质相互作用网络进行图形化展示,为其功能关系提供了高层次神力,有助于生物学过程的模块化分析(图4)。 5.权重基因共表达分析 实验服务 常规的差异表达分析方法大大促进了生物学的发展,取得了很多重大发现,但是,这些方法都忽略了基因表达模式之间的相关性。结果,这些数据产生的信息数量很多,却很难从中发现有价值的线索,无法确定差异表达基因的you先级,更难以去研究潜在的生物学通路。相反,共表达网络(又称相关性网络)可以发现彼此相关的基因(图5 A),并将其分为相应的cluster(即共表达模块)(图5 B),然后计算得到模块中权重高的基因,将其做为关键调节因子(图5 C),从而简化了数据的分析过程,能够高效的从数据中提取出关键信息,现已有大量的研究采用了这种方法。 6.高能量测序数据分析(差异基因表达、差异异构体表达、可变拼接) 实验服务 细胞内基因表达水平时刻处于变化之中,具有显著的时间、组织、条件te异性,同时许多基因还具有不同的异构体(图6.1),测定不同刺激条件下的基因及其异构体的表达变化对于阐明相关的生物学过程为重要。RNAseq技术可以一次性鉴定出大量的差异表达基因/异构体,从而在系统水平了解生命活动的机制,也可以筛选出重要基因进行更深的功能研究。 可变拼接(AS)是真核生物基因表达调控的重要机制之一。RNAseq已成为定量分析细胞内的可变拼接的强有力工具,随着高通量测序仪的不断涌现,RNSseq的数据量也在以指数形式增加。在此背景下,我们提供了可变拼接分析服务,对te定基因以及大规模转录组数据的可变拼接(图6.2 A)、差异外显子使用(图6.2 B)等进行定量分析。
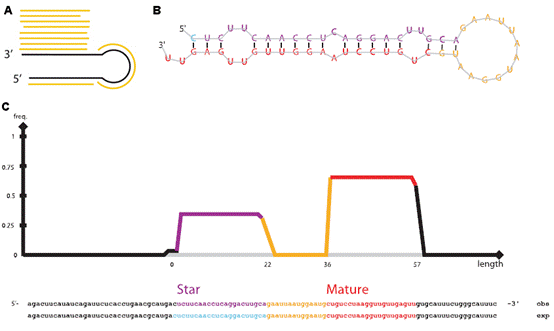
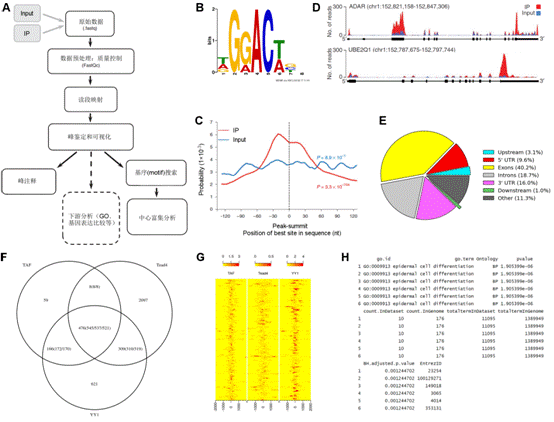
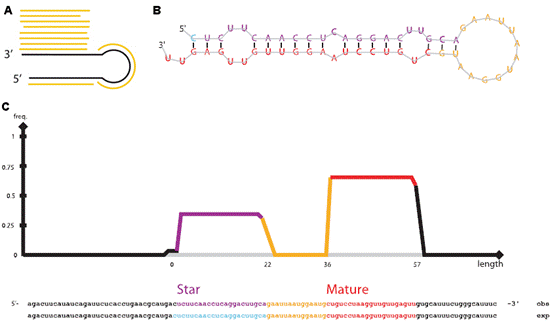
7.microRNA数据分析实验服务 MicroRNA (miRNA) 是一类由内源发卡结构转录本产生的长度约为22个核苷酸的非编码单链RNA 分子,通过与靶mRNA分子互补配对进行转录后调控。提取细胞内部RNA后进行小RNA建库,然后进行高通量测序,通过te定的算法(图7 A),由测序数据可得到已知的和新的miRNA分子前体(图7 B),并对此前体产生的miRNA进行定量(图7 C)。 8.染色质免疫共沉淀(ChIP)分析 实验服务 染色质免疫沉淀结合高通量测序技术(ChIP-seq)是鉴定基因组范围内DNA/RNA结合蛋白靶位点的标准方法,现已开始在力学生物学中得到应用,用于研究力学刺激下的蛋白质-DNA相互作用。Chip-seq手先富集目标蛋白结合的DNA/RNA片段,然后纯化和建库并进行高通量测序。得到的原始数据经过te定的数据处理流程(图8 A),可得到基因组范围内与目标蛋白互作的DNA序列信息(图8 B、C)、基因不同位置的分布(图8 D、E)、比较不同的生物学重复之间的重复性(图8 F)、结合位点热图(图8 G),并对峰相关的基因进行GO功能富集分析(图8 H)等。 9、主成分分析实验服务 10、HITS-CLIP分析 11、宏基因组分析 12、外显子测序分析 13、单细胞测序分析 |